Paul Streli
PhD student, Department of Computer Science, ETH Zürich

I am a PhD student at the Sensing, Interaction & Perception Lab at ETH Zürich with Christian Holz, supported by a Meta Research PhD Fellowship. My research is on computational interaction, human motion estimation, and applications in emerging Mixed Reality systems. Combining my background in machine learning, computer vision and signal processing, I develop learning-based perception algorithms that infer natural and precise user input and motions from passive sensor observations.
Before starting my PhD, I completed a master’s degree in Electrical & Electronic Engineering at Imperial College London. I worked as a
Research Scientist intern at Meta Reality Labs and an AI research intern at TikTok.
Please reach out via email if you want to know more about my work.
CV / Google Scholar / Github / LinkedIn / X (Twitter)
publications
-
 EgoPressure: A Dataset for Hand Pressure and Pose Estimation in Egocentric VisionYiming Zhao*, Taein Kwon*, Paul Streli*, Marc Pollefeys, Christian HolzIn Proceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2025. (Highlight (top 3%)).
EgoPressure: A Dataset for Hand Pressure and Pose Estimation in Egocentric VisionYiming Zhao*, Taein Kwon*, Paul Streli*, Marc Pollefeys, Christian HolzIn Proceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2025. (Highlight (top 3%)).
*Equal contributionTouch contact and pressure are essential for understanding how humans interact with objects and offer insights that benefit applications in mixed reality and robotics. Estimating these interactions from an egocentric camera perspective is challenging, largely due to the lack of comprehensive datasets that provide both hand poses and pressure annotations. In this paper, we present EgoPressure, an egocentric dataset that is annotated with high-resolution pressure intensities at contact points and precise hand pose meshes, obtained via our multi-view, sequence-based optimization method. We introduce baseline models for estimating applied pressure on external surfaces from RGB images, both with and without hand pose information, as well as a joint model for predicting hand pose and the pressure distribution across the hand mesh. Our experiments show that pressure and hand pose complement each other in understanding hand-object interactions.
@inproceedings{cvpr2025-egopressure, title = {EgoPressure: A Dataset for Hand Pressure and Pose Estimation in Egocentric Vision}, author = {Zhao, Yiming and Kwon, Taein and Streli, Paul and Pollefeys, Marc and Holz, Christian}, year = {2025}, booktitle = {Proceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, publisher = {IEEE Computer Society} }
-
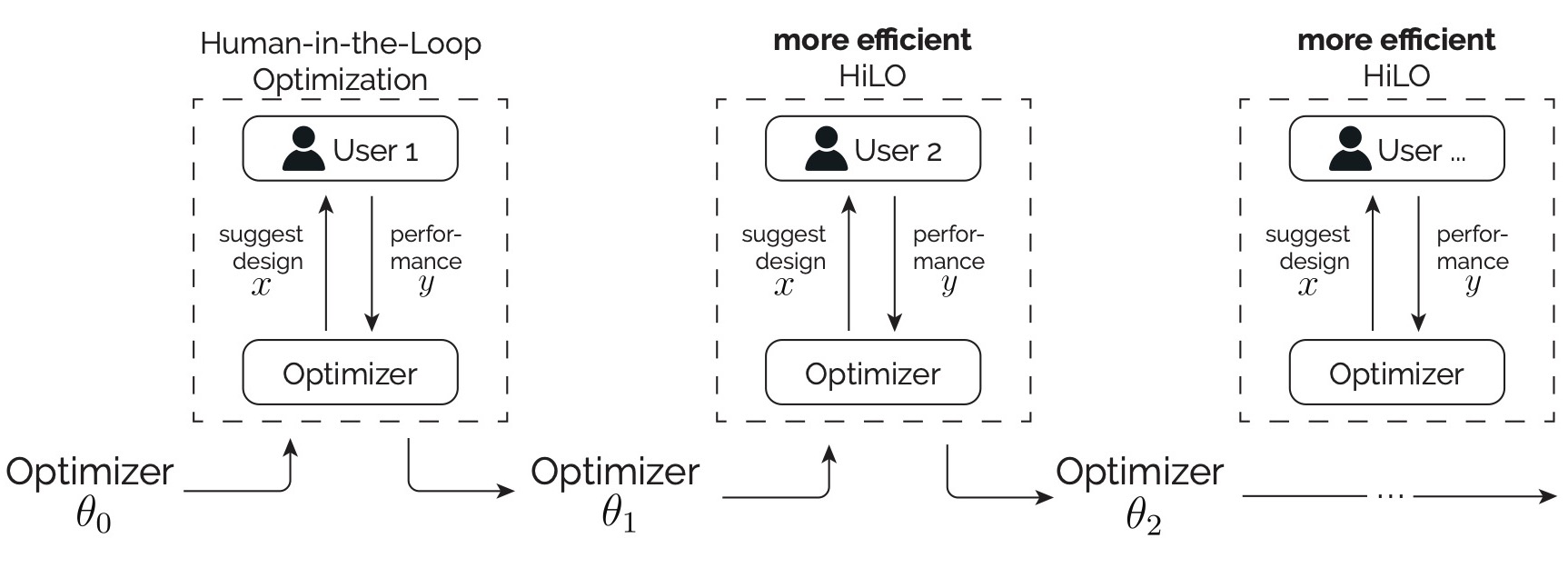 Continual Human-in-the-Loop OptimizationYi-Chi Liao, Paul Streli, Zhipeng Li, Christoph Gebhardt, Christian HolzIn Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 2025. (Honorable mention award).
Continual Human-in-the-Loop OptimizationYi-Chi Liao, Paul Streli, Zhipeng Li, Christoph Gebhardt, Christian HolzIn Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 2025. (Honorable mention award).Optimal input settings vary across users due to differences in motor abilities and personal preferences, which are typically addressed by manual tuning or calibration. Although human-in-the-loop optimization has the potential to identify optimal settings during use, it is rarely applied due to its long optimization process. A more efficient approach would continually leverage data from previous users to accelerate optimization, exploiting shared traits while adapting to individual characteristics. We introduce the concept of Continual Human-in-the-Loop Optimization and a Bayesian optimization-based method that leverages a Bayesian-neural-network surrogate model to capture population-level characteristics while adapting to new users. We propose a generative replay strategy to mitigate catastrophic forgetting. We demonstrate our method by optimizing virtual reality keyboard parameters for text entry using direct touch, showing reduced adaptation times with a growing user base. Our method opens the door for next-generation personalized input systems that improve with accumulated experience.
@inproceedings{chi2025-chilo, title = {Continual Human-in-the-Loop Optimization}, author = {Liao, Yi-Chi and Streli, Paul and Li, Zhipeng and Gebhardt, Christoph and Holz, Christian}, year = {2025}, isbn = {9798400713941}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {https://doi.org/10.1145/3706598.3713603}, booktitle = {Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems} }
-
 EgoSim: An Egocentric Multi-view Simulator and Real Dataset for Body-worn Cameras during Motion and ActivityDominik Hollidt, Paul Streli, Jiaxi Jiang, Yasaman Haghighi, Changlin Qian, Xintong Liu, Christian HolzIn The Thirty-eight Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track. 2024.
EgoSim: An Egocentric Multi-view Simulator and Real Dataset for Body-worn Cameras during Motion and ActivityDominik Hollidt, Paul Streli, Jiaxi Jiang, Yasaman Haghighi, Changlin Qian, Xintong Liu, Christian HolzIn The Thirty-eight Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track. 2024.Research on egocentric tasks in computer vision has mostly focused on head-mounted cameras, such as fisheye cameras or embedded cameras inside immersive headsets. We argue that the increasing miniaturization of optical sensors will lead to the prolific integration of cameras into many more body-worn devices at various locations. This will bring fresh perspectives to established tasks in computer vision and benefit key areas such as human motion tracking, body pose estimation, or action recognition---particularly for the lower body, which is typically occluded. In this paper, we introduce EgoSim, a novel simulator of body-worn cameras that generates realistic egocentric renderings from multiple perspectives across a wearer's body. A key feature of EgoSim is its use of real motion capture data to render motion artifacts, which are especially noticeable with arm- or leg-worn cameras. In addition, we introduce MultiEgoView, a dataset of egocentric footage from six body-worn cameras and ground-truth full-body 3D poses during several activities: 119 hours of data are derived from AMASS motion sequences in four high-fidelity virtual environments, which we augment with 5 hours of real-world motion data from 13 participants using six GoPro cameras and 3D body pose references from an Xsens motion capture suit. We demonstrate EgoSim's effectiveness by training an end-to-end video-only 3D pose estimation network. Analyzing its domain gap, we show that our dataset and simulator substantially aid training for inference on real-world data.
@inproceedings{neurips2024-egosim, title = {EgoSim: An Egocentric Multi-view Simulator and Real Dataset for Body-worn Cameras during Motion and Activity}, author = {Hollidt, Dominik and Streli, Paul and Jiang, Jiaxi and Haghighi, Yasaman and Qian, Changlin and Liu, Xintong and Holz, Christian}, booktitle = {The Thirty-eight Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track}, year = {2024} }
-
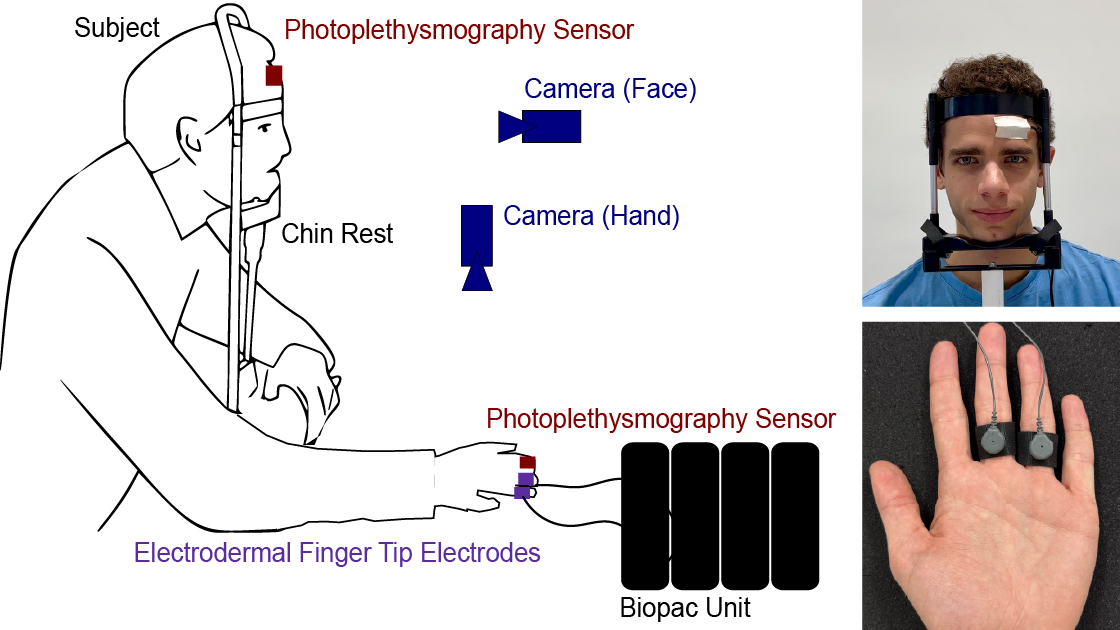 SympCam: Remote Optical Measurement of Sympathetic ArousalBjörn Braun, Daniel McDuff, Tadas Baltrusaitis, Paul Streli, Max Moebus, Christian HolzIn 2024 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI). 2024.
SympCam: Remote Optical Measurement of Sympathetic ArousalBjörn Braun, Daniel McDuff, Tadas Baltrusaitis, Paul Streli, Max Moebus, Christian HolzIn 2024 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI). 2024.Recent work has shown that a person's sympathetic arousal can be estimated from facial videos alone using basic signal processing. This opens up new possibilities in the field of telehealth and stress management, providing a non-invasive method to measure stress only using a regular RGB camera. In this paper, we present SympCam, a new 3D convolutional architecture tailored to the task of remote sympathetic arousal prediction. Our model incorporates a temporal attention module (TAM) to enhance the temporal coherence of our sequential data processing capabilities. The predictions from our method improve accuracy metrics of sympathetic arousal in prior work by 48% to a mean correlation of 0.77. We additionally compare our method with common remote photoplethysmography (rPPG) networks and show that they alone cannot accurately predict sympathetic arousal 'out-of-the-box'. Furthermore, we show that the sympathetic arousal predicted by our method allows detecting physical stress with a balanced accuracy of 90% - an improvement of 61% compared to the rPPG method commonly used in related work, demonstrating the limitations of using rPPG alone. Finally, we contribute a dataset designed explicitly for the task of remote sympathetic arousal prediction. Our dataset contains synchronized face and hand videos of 20 participants from two cameras synchronized with electrodermal activity (EDA) and photoplethysmography (PPG) measurements. We will make this dataset available to the community and use it to evaluate the methods in this paper. To the best of our knowledge, this is the first dataset available to other researchers designed for remote sympathetic arousal prediction.
@inproceedings{bhi2024-sympcam, author = {Braun, Bj{\"o}rn and McDuff, Daniel and Baltrusaitis, Tadas and Streli, Paul and Moebus, Max and Holz, Christian}, title = {SympCam: Remote Optical Measurement of Sympathetic Arousal}, year = {2024}, booktitle = {2024 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI)} }
-
 TouchInsight: Uncertainty-aware Rapid Touch and Text Input for Mixed Reality from Egocentric VisionPaul Streli, Mark Richardson, Fadi Botros, Shugao Ma, Robert Wang, Christian HolzIn Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST). 2024.
TouchInsight: Uncertainty-aware Rapid Touch and Text Input for Mixed Reality from Egocentric VisionPaul Streli, Mark Richardson, Fadi Botros, Shugao Ma, Robert Wang, Christian HolzIn Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST). 2024.While passive surfaces offer numerous benefits for interaction in mixed reality, reliably detecting touch input solely from head-mounted cameras has been a long-standing challenge. Camera specifics, hand self-occlusion, and rapid movements of both head and fingers introduce considerable uncertainty about the exact location of touch events. Existing methods have thus not been capable of achieving the performance needed for robust interaction.
In this paper, we present a real-time pipeline that detects touch input from all ten fingers on any physical surface, purely based on egocentric hand tracking. Our method TouchInsight comprises a neural network to predict the moment of a touch event, the finger making contact, and the touch location. TouchInsight represents locations through a bivariate Gaussian distribution to account for uncertainties due to sensing inaccuracies, which we resolve through contextual priors to accurately infer intended user input.
We first evaluated our method offline and found that it locates input events with a mean error of 6.3 mm, and accurately detects touch events (F1=0.99) and identifies the finger used (F1=0.96). In an online evaluation, we then demonstrate the effectiveness of our approach for a core application of dexterous touch input: two-handed text entry. In our study, participants typed 37.0 words per minute with an uncorrected error rate of 2.9% on average.@inproceedings{uist2024-touchinsight, author = {Streli, Paul and Richardson, Mark and Botros, Fadi and Ma, Shugao and Wang, Robert and Holz, Christian}, title = {TouchInsight: Uncertainty-aware Rapid Touch and Text Input for Mixed Reality from Egocentric Vision}, year = {2024}, pages = {1--16}, isbn = {9798400706288}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {https://doi.org/10.1145/3654777.3676330}, booktitle = {Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST)} }
-
 SituationAdapt: Contextual UI Optimization in Mixed Reality with Situation Awareness via LLM ReasoningZhipeng Li, Christoph Gebhardt, Yves Inglin, Nicolas Steck, Paul Streli, Christian HolzIn Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST). 2024.
SituationAdapt: Contextual UI Optimization in Mixed Reality with Situation Awareness via LLM ReasoningZhipeng Li, Christoph Gebhardt, Yves Inglin, Nicolas Steck, Paul Streli, Christian HolzIn Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST). 2024.Mixed Reality is increasingly used in mobile settings beyond controlled home and office spaces. This mobility introduces the need for user interface layouts that adapt to varying contexts. However, existing adaptive systems are designed only for static environments. In this paper, we introduce *SituationAdapt*, a system that adjusts Mixed Reality UIs to real-world surroundings by considering environmental and social cues in shared settings. Our system consists of perception, reasoning, and optimization modules for UI adaptation. Our perception module identifies objects and individuals around the user, while our reasoning module leverages a Vision-and-Language Model to assess the placement of interactive UI elements. This ensures that adapted layouts do not obstruct relevant environmental cues or interfere with social norms. Our optimization module then generates Mixed Reality interfaces that account for these considerations as well as temporal constraints The evaluation of SituationAdapt is two-fold: We first validate our reasoning component’s capability in assessing UI contexts comparable to human expert users. In an online user study, we then established our system’s capability of producing context-aware MR layouts, where it outperformed adaptive methods from previous work. We further demonstrate the versatility and applicability of SituationAdapt with a set of application scenarios.
@inproceedings{uist2024-situationadapt, author = {Li, Zhipeng and Gebhardt, Christoph and Inglin, Yves and Steck, Nicolas and Streli, Paul and Holz, Christian}, title = {SituationAdapt: Contextual UI Optimization in Mixed Reality with Situation Awareness via LLM Reasoning}, year = {2024}, pages = {1--13}, isbn = {9798400706288}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {https://doi.org/10.1145/3654777.3676470}, booktitle = {Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST)} }
-
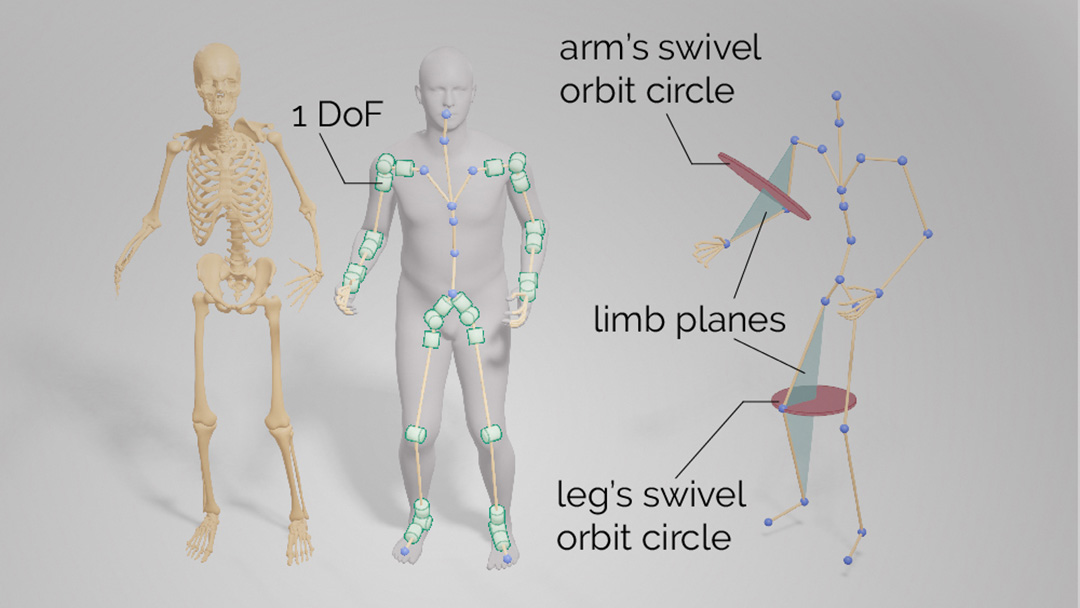 MANIKIN: Biomechanically Accurate Neural Inverse Kinematics for Human Motion EstimationJiaxi Jiang, Paul Streli, Xuejing Luo, Christoph Gebhardt, Christian HolzIn Proceedings of the European Conference on Computer Vision (ECCV). 2024.
MANIKIN: Biomechanically Accurate Neural Inverse Kinematics for Human Motion EstimationJiaxi Jiang, Paul Streli, Xuejing Luo, Christoph Gebhardt, Christian HolzIn Proceedings of the European Conference on Computer Vision (ECCV). 2024.Mixed Reality systems aim to estimate a user's full-body joint configurations from just the pose of the end effectors, primarily head and hand poses. Existing methods often involve solving inverse kinematics (IK) to obtain the full skeleton from just these sparse observations, usually directly optimizing the joint angle parameters of a human skeleton. Since this accumulates error through the kinematic tree, predicted end effector poses fail to align with the provided input pose. This leads to discrepancies between the predicted and the actual hand positions or feet that penetrate the ground. In this paper, we first refine the commonly used SMPL parametric model by embedding anatomical constraints that reduce the degrees of freedom for specific parameters to more closely mirror human biomechanics. This ensures that our model produces physically plausible pose predictions. We then propose a biomechanically accurate neural inverse kinematics solver (MANIKIN) for full-body motion tracking. MANIKIN is based on swivel angle prediction and perfectly matches input poses while avoiding ground penetration. We evaluate MANIKIN in extensive experiments on motion capture datasets and demonstrate that our method surpasses the state of the art in quantitative and qualitative results at fast inference speed.
@inproceedings{eccv2024-manikin, title = {MANIKIN: Biomechanically Accurate Neural Inverse Kinematics for Human Motion Estimation}, author = {Jiang, Jiaxi and Streli, Paul and Luo, Xuejing and Gebhardt, Christoph and Holz, Christian}, booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)}, year = {2024}, organization = {Springer} }
-
 EgoPoser: Robust Real-Time Egocentric Pose Estimation from Sparse and Intermittent Observations EverywhereJiaxi Jiang, Paul Streli, Manuel Meier, Christian HolzIn Proceedings of the European Conference on Computer Vision (ECCV). 2024.
EgoPoser: Robust Real-Time Egocentric Pose Estimation from Sparse and Intermittent Observations EverywhereJiaxi Jiang, Paul Streli, Manuel Meier, Christian HolzIn Proceedings of the European Conference on Computer Vision (ECCV). 2024.Full-body egocentric pose estimation from head and hand poses alone has become an active area of research to power articulate avatar representations on headset-based platforms. However, existing methods over-rely on the indoor motion-capture spaces in which datasets were recorded, while simultaneously assuming continuous joint motion capture and uniform body dimensions. We propose EgoPoser to overcome these limitations with four main contributions. 1) EgoPoser robustly models body pose from intermittent hand position and orientation tracking only when inside a headset's field of view. 2) We rethink input representations for headset-based ego-pose estimation and introduce a novel global motion decomposition method that predicts full-body pose independent of global positions. 3) We enhance pose estimation by capturing longer motion time series through an efficient SlowFast module design that maintains computational efficiency. 4) EgoPoser generalizes across various body shapes for different users. We experimentally evaluate our method and show that it outperforms state-of-the-art methods both qualitatively and quantitatively while maintaining a high inference speed of over 600 fps. EgoPoser establishes a robust baseline for future work where full-body pose estimation no longer needs to rely on outside-in capture and can scale to large-scale and unseen environments.
@inproceedings{eccv2024-egoposer, author = {Jiang, Jiaxi and Streli, Paul and Meier, Manuel and Holz, Christian}, title = {EgoPoser: Robust Real-Time Egocentric Pose Estimation from Sparse and Intermittent Observations Everywhere}, booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)}, year = {2024}, organization = {Springer} }
-
 Structured Light Speckle: Joint Ego-Centric Depth Estimation and Low-Latency Contact Detection via Remote VibrometryPaul Streli, Jiaxi Jiang, Juliete Rossie, Christian HolzIn Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST). 2023.
Structured Light Speckle: Joint Ego-Centric Depth Estimation and Low-Latency Contact Detection via Remote VibrometryPaul Streli, Jiaxi Jiang, Juliete Rossie, Christian HolzIn Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST). 2023.Despite advancements in egocentric hand tracking using head-mounted cameras, contact detection with real-world objects remains challenging, particularly for the quick motions often performed during interaction in Mixed Reality. In this paper, we introduce a novel method for detecting touch on discovered physical surfaces purely from an egocentric perspective using optical sensing. We leverage structured laser light to detect real-world surfaces from the disparity of reflections in real-time and, at the same time, extract a time series of remote vibrometry sensations from laser speckle motions. The pattern caused by structured laser light reflections enables us to simultaneously sample the mechanical vibrations that propagate through the user's hand and the surface upon touch. We integrated Structured Light Speckle into TapLight, a prototype system that is a simple add-on to Mixed Reality headsets. In our evaluation with a Quest 2, TapLight—while moving—reliably detected horizontal and vertical surfaces across a range of surface materials. TapLight also reliably detected rapid touch contact and robustly discarded other hand motions to prevent triggering spurious input events. Despite the remote sensing principle of Structured Light Speckle, our method achieved a latency for event detection in realistic settings that matches body-worn inertial sensing without needing such additional instrumentation. We conclude with a series of VR demonstrations for situated interaction that leverage the quick touch interaction TapLight supports.
@inproceedings{uist2023-structured_light_speckle, author = {Streli, Paul and Jiang, Jiaxi and Rossie, Juliete and Holz, Christian}, title = {Structured Light Speckle: Joint Ego-Centric Depth Estimation and Low-Latency Contact Detection via Remote Vibrometry}, year = {2023}, isbn = {9798400701320}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {https://doi.org/10.1145/3586183.3606749}, booktitle = {Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST)}, articleno = {26}, numpages = {12} }
-
 ViGather: Inclusive Virtual Conferencing with a Joint Experience Across Traditional Screen Devices and Mixed Reality HeadsetsHuajian Qiu, Paul Streli, Tiffany Luong, Christoph Gebhardt, Christian HolzIn Proceedings of the ACM Conference on Mobile Human-Computer Interaction. 2023.
ViGather: Inclusive Virtual Conferencing with a Joint Experience Across Traditional Screen Devices and Mixed Reality HeadsetsHuajian Qiu, Paul Streli, Tiffany Luong, Christoph Gebhardt, Christian HolzIn Proceedings of the ACM Conference on Mobile Human-Computer Interaction. 2023.Teleconferencing is poised to become one of the most frequent use cases of immersive platforms, since it supports high levels of presence and embodiment in collaborative settings. On desktop and mobile platforms, teleconferencing solutions are already among the most popular apps and accumulate significant usage time—not least due to the pandemic or as a desirable substitute for air travel or commuting. In this paper, we present ViGather, an immersive teleconferencing system that integrates users of all platform types into a joint experience via equal representation and a first-person experience. ViGather renders all participants as embodied avatars in one shared scene to establish co-presence and elicit natural behavior during collocated conversations, including nonverbal communication cues such as eye contact between participants as well as body language such as turning one's body to another person or using hand gestures to emphasize parts of a conversation during the virtual hangout. Since each user embodies an avatar and experiences situated meetings from an egocentric perspective no matter the device they join from, ViGather alleviates potential concerns about self-perception and appearance while mitigating potential 'Zoom fatigue', as users' self-views are not shown. For participants in Mixed Reality, our system leverages the rich sensing and reconstruction capabilities of today's headsets. For users of tablets, laptops, or PCs, ViGather reconstructs the user's pose from the device's front-facing camera, estimates eye contact with other participants, and relates these non-verbal cues to immediate avatar animations in the shared scene. Our evaluation compared participants' behavior and impressions while videoconferencing in groups of four inside ViGather with those in Meta Horizon as a baseline for a social VR setting. Participants who participated on traditional screen devices (e.g., laptops and desktops) using ViGather reported a significantly higher sense of physical, spatial, and self-presence than when using Horizon, while all perceived similar levels of active social presence when using Virtual Reality headsets. Our follow-up study confirmed the importance of representing users on traditional screen devices as reconstructed avatars for perceiving self-presence.
@inproceedings{mhci2023-vigather, title = {ViGather: Inclusive Virtual Conferencing with a Joint Experience Across Traditional Screen Devices and Mixed Reality Headsets}, author = {Qiu, Huajian and Streli, Paul and Luong, Tiffany and Gebhardt, Christoph and Holz, Christian}, booktitle = {Proceedings of the ACM Conference on Mobile Human-Computer Interaction}, volume = {7}, pages = {1--27}, year = {2023}, doi = {https://doi.org/10.1145/3604279}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA} }
-
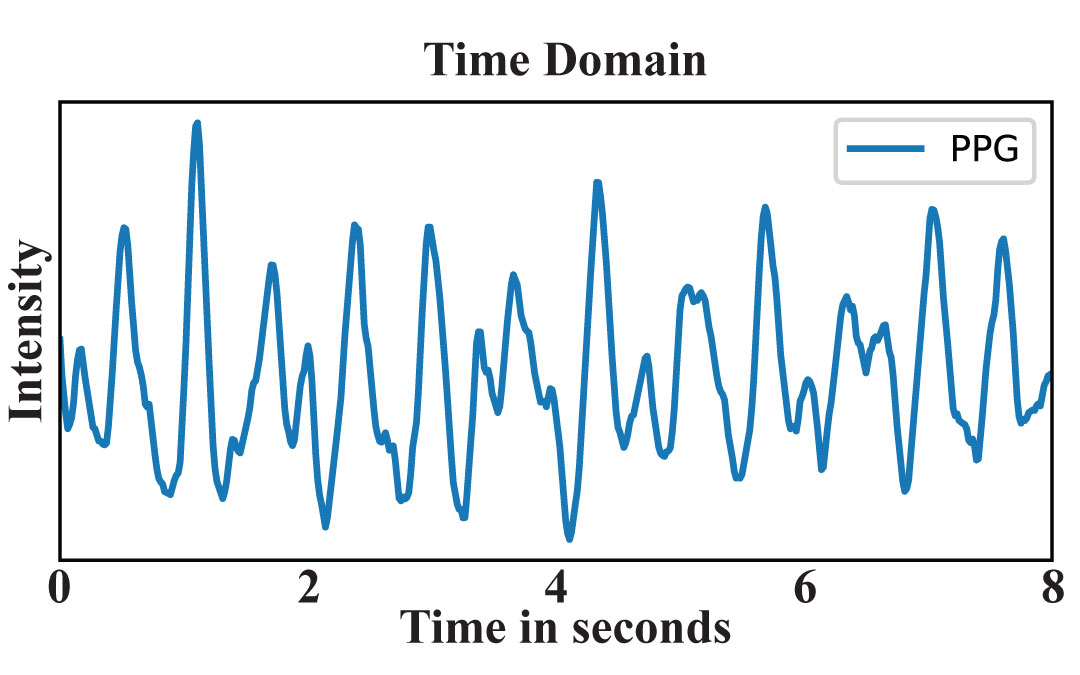 BeliefPPG: Uncertainty-aware Heart Rate Estimation from PPG signals via Belief PropagationValentin Bieri*, Paul Streli*, Berken Utku Demirel, Christian HolzIn Conference on Uncertainty in Artificial Intelligence (UAI). 2023.
BeliefPPG: Uncertainty-aware Heart Rate Estimation from PPG signals via Belief PropagationValentin Bieri*, Paul Streli*, Berken Utku Demirel, Christian HolzIn Conference on Uncertainty in Artificial Intelligence (UAI). 2023.
*Equal contributionWe present a novel learning-based method that achieves state-of-the-art performance on several heart rate estimation benchmarks extracted from photoplethysmography signals (PPG). We consider the evolution of the heart rate in the context of a discrete-time stochastic process that we represent as a hidden Markov model. We derive a distribution over possible heart rate values for a given PPG signal window through a trained neural network. Using belief propagation, we incorporate the statistical distribution of heart rate changes to refine these estimates in a temporal context. From this, we obtain a quantized probability distribution over the range of possible heart rate values that captures a meaningful and well-calibrated estimate of the inherent predictive uncertainty. We show the robustness of our method on eight public datasets with three different cross-validation experiments.
@inproceedings{uai2023-beliefppg, author = {Bieri, Valentin and Streli, Paul and Demirel, Berken Utku and Holz, Christian}, title = {BeliefPPG: Uncertainty-aware Heart Rate Estimation from PPG signals via Belief Propagation}, year = {2023}, organization = {PMLR}, booktitle = {Conference on Uncertainty in Artificial Intelligence (UAI)} }
-
 HOOV: Hand Out-Of-View Tracking for Proprioceptive Interaction using Inertial SensingPaul Streli, Rayan Armani, Yi Fei Cheng, Christian HolzIn Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 2023.
HOOV: Hand Out-Of-View Tracking for Proprioceptive Interaction using Inertial SensingPaul Streli, Rayan Armani, Yi Fei Cheng, Christian HolzIn Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 2023.Current Virtual Reality systems are designed for interaction under visual control. Using built-in cameras, headsets track the user's hands or hand-held controllers while they are inside the field of view. Current systems thus ignore the user's interaction with off-screen content—virtual objects that the user could quickly access through proprioception without requiring laborious head motions to bring them into focus. In this paper, we present HOOV, a wrist-worn sensing method that allows VR users to interact with objects outside their field of view. Based on the signals of a single wrist-worn inertial sensor, HOOV continuously estimates the user's hand position in 3-space to complement the headset's tracking as the hands leave the tracking range. Our novel data-driven method predicts hand positions and trajectories from just the continuous estimation of hand orientation, which by itself is stable based solely on inertial observations. Our inertial sensing simultaneously detects finger pinching to register off-screen selection events, confirms them using a haptic actuator inside our wrist device, and thus allows users to select, grab, and drop virtual content. We compared HOOV's performance with a camera-based optical motion capture system in two folds. In the first evaluation, participants interacted based on tracking information from the motion capture system to assess the accuracy of their proprioceptive input, whereas in the second, they interacted based on HOOV's real-time estimations. We found that HOOV's target-agnostic estimations had a mean tracking error of 7.7 cm, which allowed participants to reliably access virtual objects around their body without first bringing them into focus. We demonstrate several applications that leverage the larger input space HOOV opens up for quick proprioceptive interaction, and conclude by discussing the potential of our technique.
@inproceedings{chi2023-hoov, author = {Streli, Paul and Armani, Rayan and Cheng, Yi Fei and Holz, Christian}, title = {HOOV: Hand Out-Of-View Tracking for Proprioceptive Interaction using Inertial Sensing}, year = {2023}, isbn = {9781450394215}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {https://doi.org/10.1145/3544548.3581468}, booktitle = {Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems}, numpages = {1--15} }
-
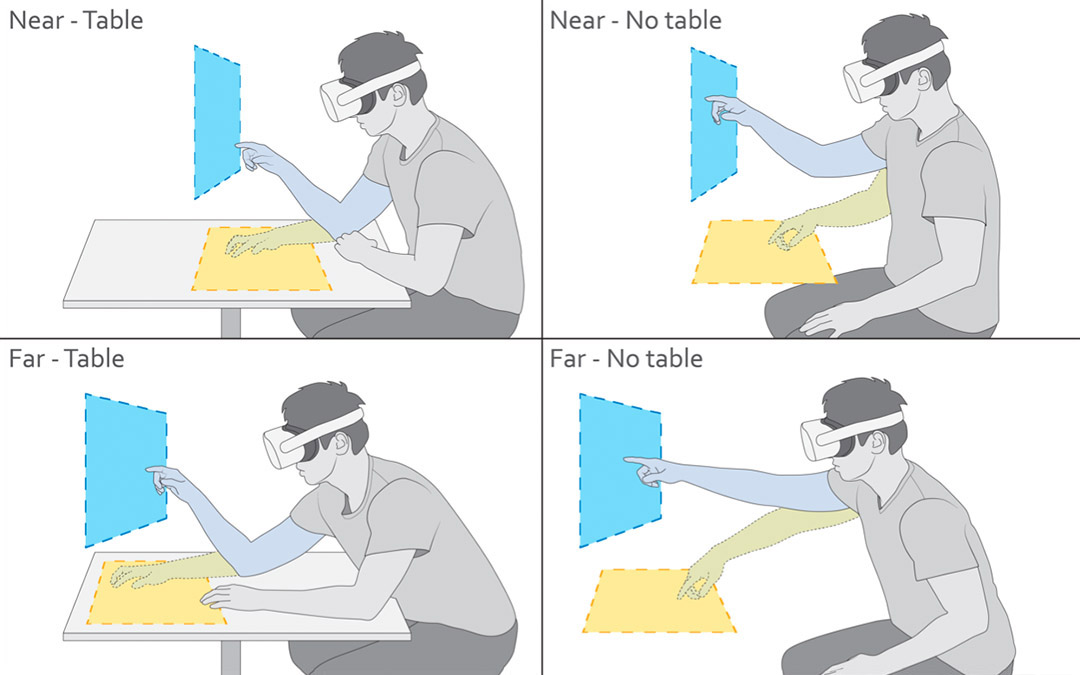 ComforTable User Interfaces: Surfaces Reduce Input Error, Time, and Exertion for Tabletop and Mid-air User InterfacesYi Fei Cheng, Tiffany Luong, Andreas Rene Fender, Paul Streli, Christian HolzIn 2022 IEEE International Symposium on Mixed and Augmented Reality (ISMAR). 2022.
ComforTable User Interfaces: Surfaces Reduce Input Error, Time, and Exertion for Tabletop and Mid-air User InterfacesYi Fei Cheng, Tiffany Luong, Andreas Rene Fender, Paul Streli, Christian HolzIn 2022 IEEE International Symposium on Mixed and Augmented Reality (ISMAR). 2022.Real-world work-spaces typically revolve around tables, which enable knowledge workers to comfortably perform tasks over an extended period of time during productivity tasks. Tables afford more ergonomic postures and provide opportunities for rest, which raises the question of whether they may also benefit prolonged interaction in Virtual Reality (VR). In this paper, we investigate the effects of tabletop surface presence in situated VR settings on task performance, behavior, and subjective experience. In an empirical study, 24 participants performed two tasks (selection, docking) on virtual interfaces placed at two distances and two orientations. Our results show that a physical tabletop inside VR improves comfort, agency, and task performance while decreasing physical exertion and strain of the neck, shoulder, elbow, and wrist, assessed through objective metrics and subjective reporting. Notably, we found that these benefits apply when the UI is placed on and aligned with the table itself as well as when it is positioned vertically in mid-air above it. Our experiment therefore provides empirical evidence for integrating physical table surfaces into VR scenarios to enable and support prolonged interaction. We conclude by discussing the effective usage of surfaces in situated VR experiences and provide initial guidelines.
@inproceedings{ismar2022-comfortableUIs, author = {Cheng, Yi Fei and Luong, Tiffany and Fender, Andreas Rene and Streli, Paul and Holz, Christian}, title = {ComforTable User Interfaces: Surfaces Reduce Input Error, Time, and Exertion for Tabletop and Mid-air User Interfaces}, year = {2022}, booktitle = {2022 IEEE International Symposium on Mixed and Augmented Reality (ISMAR)}, organization = {IEEE} }
-
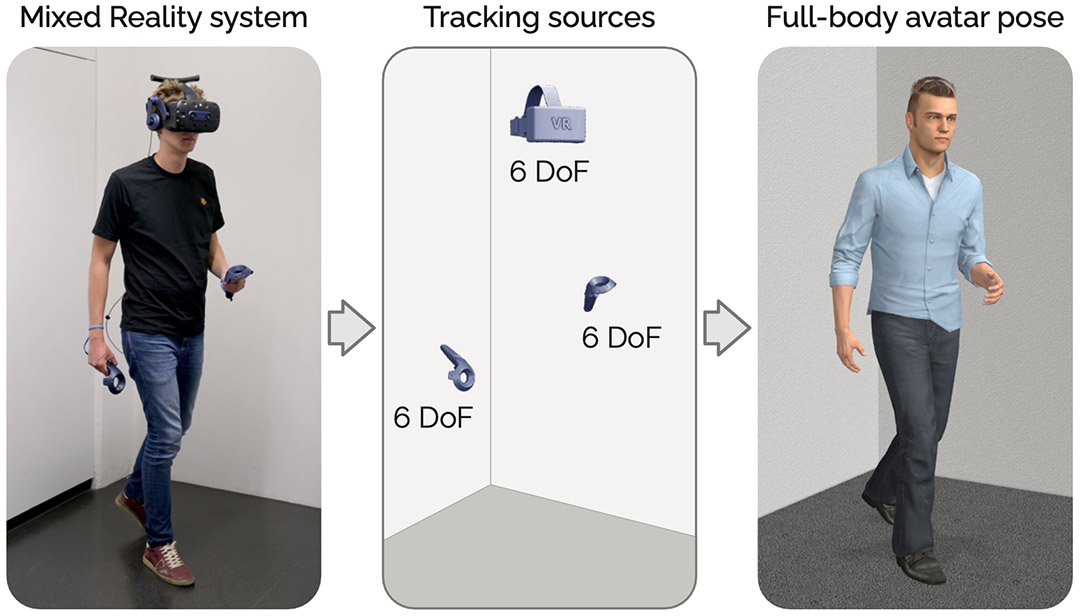 AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion SensingJiaxi Jiang, Paul Streli, Huajian Qiu, Andreas Fender, Larissa Laich, Patrick Snape, Christian HolzIn Proceedings of the European Conference on Computer Vision (ECCV). 2022.
AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion SensingJiaxi Jiang, Paul Streli, Huajian Qiu, Andreas Fender, Larissa Laich, Patrick Snape, Christian HolzIn Proceedings of the European Conference on Computer Vision (ECCV). 2022.Today’s Mixed Reality head-mounted displays track the user’s head pose in world space as well as the user’s hands for interaction in both Augmented Reality and Virtual Reality scenarios. While this is adequate to support user input, it unfortunately limits users’ virtual representations to just their upper bodies. Current systems thus resort to floating avatars, whose limitation is particularly evident in collaborative settings. To estimate full-body poses from the sparse input sources, prior work has incorporated additional trackers and sensors at the pelvis or lower body, which increases setup complexity and limits practical application in mobile settings. In this paper, we present AvatarPoser, the first learning-based method that predicts full-body poses in world coordinates using only motion input from the user’s head and hands. Our method builds on a Transformer encoder to extract deep features from the input signals and decouples global motion from the learned local joint orientations to guide pose estimation. To obtain accurate full-body motions that resemble motion capture animations, we refine the arm joints’ positions using an optimization routine with inverse kinematics to match the original tracking input. In our evaluation, AvatarPoser achieved new state-of-the-art results in evaluations on large motion capture datasets (AMASS). At the same time, our method’s inference speed supports real-time operation, providing a practical interface to support holistic avatar control and representation for Metaverse applications.
@inproceedings{eccv2022-avatarposer, author = {Jiang, Jiaxi and Streli, Paul and Qiu, Huajian and Fender, Andreas and Laich, Larissa and Snape, Patrick and Holz, Christian}, title = {AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion Sensing}, year = {2022}, booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)} }
-
 TapType: Ten-finger text entry on everyday surfaces via Bayesian inferencePaul Streli, Jiaxi Jiang, Andreas Fender, Manuel Meier, Hugo Romat, Christian HolzIn Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 2022.
TapType: Ten-finger text entry on everyday surfaces via Bayesian inferencePaul Streli, Jiaxi Jiang, Andreas Fender, Manuel Meier, Hugo Romat, Christian HolzIn Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 2022.Despite the advent of touchscreens, typing on physical keyboards remains most efficient for entering text, because users can leverage all fingers across a full-size keyboard for convenient typing. As users increasingly type on the go, text input on mobile and wearable devices has had to compromise on full-size typing. In this paper, we present TapType, a mobile text entry system for full-size typing on passive surfaces—without an actual keyboard. From the inertial sensors inside a band on either wrist, TapType decodes and relates surface taps to a traditional QWERTY keyboard layout. The key novelty of our method is to predict the most likely character sequences by fusing the finger probabilities from our Bayesian neural network classifier with the characters' prior probabilities from an n-gram language model. In our online evaluation, participants on average typed 19 words per minute with a character error rate of 0.6% after 30 minutes of training. Expert typists thereby consistently achieved more than 25 WPM at a similar error rate. We demonstrate applications of TapType in mobile use around smartphones and tablets, as a complement to interaction in situated Mixed Reality outside visual control, and as an eyes-free mobile text input method using an audio feedback-only interface.
@inproceedings{chi2022-taptype, author = {Streli, Paul and Jiang, Jiaxi and Fender, Andreas and Meier, Manuel and Romat, Hugo and Holz, Christian}, title = {TapType: Ten-finger text entry on everyday surfaces via Bayesian inference}, year = {2022}, isbn = {9781450391573}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {https://doi.org/10.1145/3491102.3501878}, booktitle = {Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems}, numpages = {1--16} }
-
 TouchPose: Hand Pose Prediction, Depth Estimation, and Touch Classification from Capacitive ImagesKaran Ahuja, Paul Streli, Christian HolzIn Proceedings of the 34th Annual ACM Symposium on User Interface Software and Technology (UIST). 2021.
TouchPose: Hand Pose Prediction, Depth Estimation, and Touch Classification from Capacitive ImagesKaran Ahuja, Paul Streli, Christian HolzIn Proceedings of the 34th Annual ACM Symposium on User Interface Software and Technology (UIST). 2021.Today's touchscreen devices commonly detect the coordinates of user input using capacitive sensing. Yet, these coordinates are the mere 2D manifestations of the more complex 3D configuration of the whole hand—a sensation that touchscreen devices so far remain oblivious to In this work, we introduce the problem of reconstructing a 3D hand skeleton from capacitive images, which encode the sparse observations captured by touch sensors. These low-resolution images represent intensity mappings that are proportional to the distance to the user's fingers and hands. We present the first dataset of capacitive images with corresponding depth maps and 3D hand pose coordinates, comprising 65,374 aligned records from 10 participants. We introduce our supervised method TouchPose, which learns a 3D hand model and a corresponding depth map using a cross-modal trained embedding from capacitive images in our dataset. We quantitatively evaluate TouchPose's accuracy in touch contact classification, depth estimation, and 3D joint reconstruction, showing that our model generalizes to hand poses it has never seen during training and that it can infer joints that lie outside the touch sensor's volume. Enabled by TouchPose, we demonstrate a series of interactive apps and novel interactions on multitouch devices. These applications show TouchPose's versatile capability to serve as a general-purpose model, operating independent of use-case, and establishing 3D hand pose as an integral part of the input dictionary for application designers and developers. We also release our dataset, code, and model to enable future work in this domain.
@inproceedings{uist2021-touchpose, author = {Ahuja, Karan and Streli, Paul and Holz, Christian}, title = {TouchPose: Hand Pose Prediction, Depth Estimation, and Touch Classification from Capacitive Images}, year = {2021}, isbn = {9781450386357}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {https://doi.org/10.1145/3472749.3474801}, booktitle = {Proceedings of the 34th Annual ACM Symposium on User Interface Software and Technology (UIST)}, pages = {997–1009}, numpages = {13} }
-
 CapContact: Super-Resolution Contact Areas from Capacitive TouchscreensPaul Streli, Christian HolzIn Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 2021. (Best paper award).
CapContact: Super-Resolution Contact Areas from Capacitive TouchscreensPaul Streli, Christian HolzIn Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 2021. (Best paper award).Touch input is dominantly detected using mutual-capacitance sensing, which measures the proximity of close-by objects that change the electric field between the sensor lines. The exponential drop-off in intensities with growing distance enables software to detect touch events, but does not reveal true contact areas. In this paper, we introduce CapContact, a novel method to precisely infer the contact area between the user's finger and the surface from a single capacitive image. At 8x super-resolution, our convolutional neural network generates refined touch masks from 16-bit capacitive images as input, which can even discriminate adjacent touches that are not distinguishable with existing methods. We trained and evaluated our method using supervised learning on data from 10 participants who performed touch gestures. Our capture apparatus integrates optical touch sensing to obtain ground-truth contact through high-resolution frustrated total internal reflection. We compare our method with a baseline using bicubic upsampling as well as the ground truth from FTIR images. We separately evaluate our method's performance in discriminating adjacent touches. CapContact successfully separated closely adjacent touch contacts in 494 of 570 cases (87%) compared to the baseline's 43 of 570 cases (8%). Importantly, we demonstrate that our method accurately performs even at half of the sensing resolution at twice the grid-line pitch across the same surface area, challenging the current industry-wide standard of a ∼4mm sensing pitch. We conclude this paper with implications for capacitive touch sensing in general and for touch-input accuracy in particular.
@inproceedings{chi2021-capcontact, author = {Streli, Paul and Holz, Christian}, title = {CapContact: Super-Resolution Contact Areas from Capacitive Touchscreens}, year = {2021}, isbn = {9781450380966}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, doi = {https://doi.org/10.1145/3411764.3445621}, booktitle = {Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems}, articleno = {289}, numpages = {14} }
-
 TapID: Rapid Touch Interaction in Virtual Reality using Wearable SensingManuel Meier, Paul Streli, Andreas Fender, Christian HolzIn 2021 IEEE Virtual Reality and 3D User Interfaces (VR). 2021. (Accompanying demo received best demonstration award (juried)).
TapID: Rapid Touch Interaction in Virtual Reality using Wearable SensingManuel Meier, Paul Streli, Andreas Fender, Christian HolzIn 2021 IEEE Virtual Reality and 3D User Interfaces (VR). 2021. (Accompanying demo received best demonstration award (juried)).Current Virtual Reality systems typically use cameras to capture user input from controllers or free-hand mid-air interaction. In this paper, we argue that this is a key impediment to productivity scenarios in VR, which require continued interaction over prolonged periods of time-a requirement that controller or free-hand input in mid-air does not satisfy. To address this challenge, we bring rapid touch interaction on surfaces to Virtual Reality-the input modality that users have grown used to on phones and tablets for continued use. We present TapID, a wrist-based inertial sensing system that complements headset-tracked hand poses to trigger input in VR. TapID embeds a pair of inertial sensors in a flexible strap, one at either side of the wrist; from the combination of registered signals, TapID reliably detects surface touch events and, more importantly, identifies the finger used for touch. We evaluated TapID in a series of user studies on event-detection accuracy (F1 = 0.997) and hand-agnostic finger-identification accuracy (within-user: F1 = 0.93; across users: F1 = 0.91 after 10 refinement taps and F1 = 0.87 without refinement) in a seated table scenario. We conclude with a series of applications that complement hand tracking with touch input and that are uniquely enabled by TapID, including UI control, rapid keyboard typing and piano playing, as well as surface gestures.
@inproceedings{vr2021-TapID, author = {Meier, Manuel and Streli, Paul and Fender, Andreas and Holz, Christian}, booktitle = {2021 IEEE Virtual Reality and 3D User Interfaces (VR)}, title = {TapID: Rapid Touch Interaction in Virtual Reality using Wearable Sensing}, year = {2021}, volume = {}, number = {}, pages = {519-528}, doi = {https://doi.org/10.1109/VR50410.2021.00076} }